
Microservices Architecture
Architecture blocks
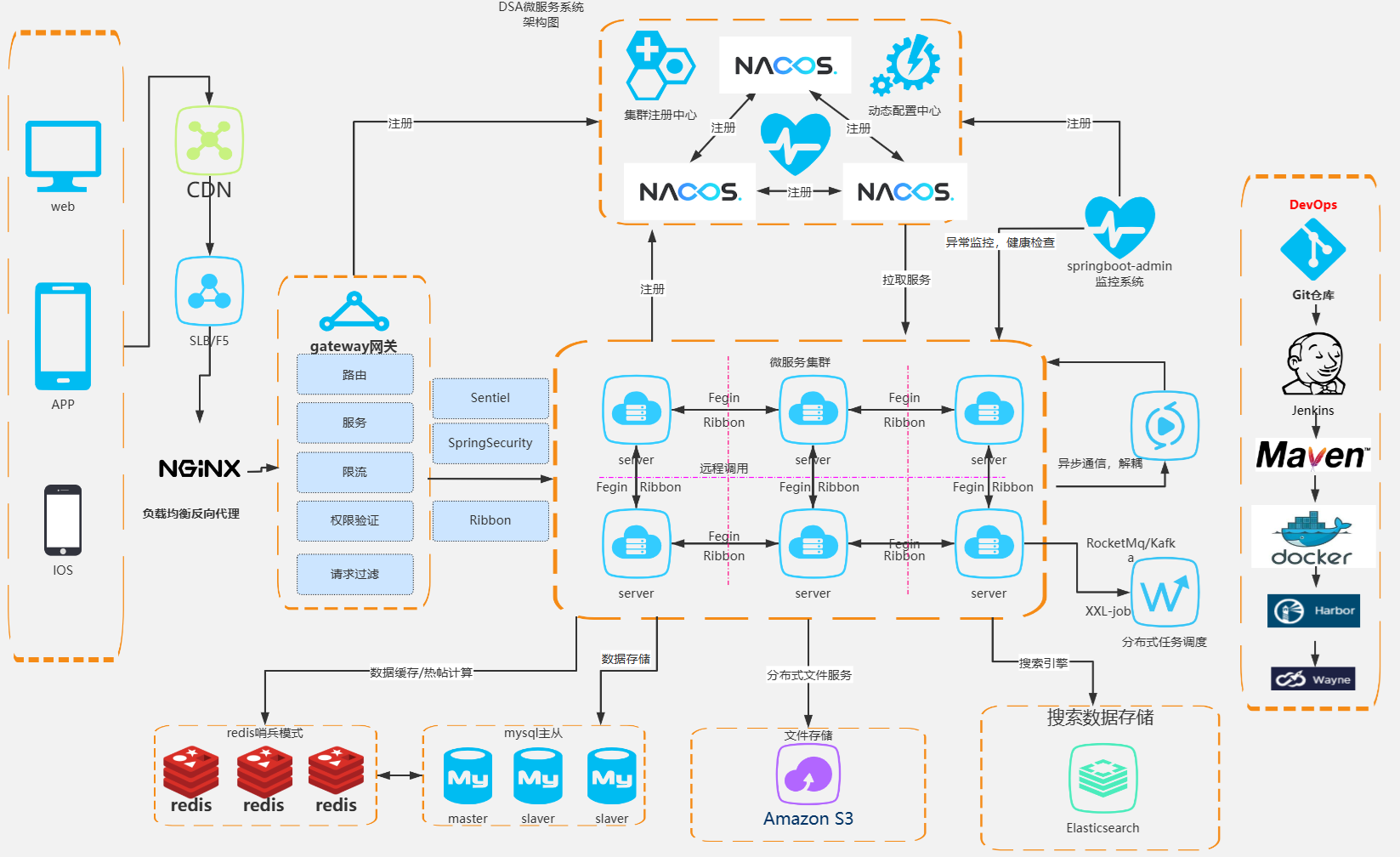
CDN
Content Delivery Network (CDN) is mainly used to improve the loading speed of websites or applications, reduce server pressure, and enhance user experience. In projects, this service is generally implemented by selecting a CDN provider.
In mainland China, there are various cloud service providers such as Alibaba Cloud and Tencent Cloud. Overseas, there are providers like Cloudflare and AWS CloudFront.
Function
CDN is mainly used for distributing static resources and large files.
Integrating CDN
There are two main methods: CNAME and reverse proxy.
- CNAME, configure the binding of the CDN domain name to the origin domain name in the CDN service console.
- Reverse proxy, configure proxy_pass in Nginx to let the CDN proxy your server.
Caching Strategy
- Strong cache (browser-side), set the Cache-Control header, such as max-age=86400 (cache for 1 day), or the ETag header (automatically invalidates when the file changes).
- CDN-side cache, common strategies are:
- Long-term caching of static resources (JS/CSS/images max-age=30d).
- Short-term caching of API data (GET requests max-age=10s).
- URL version control, such as main.css?v=202402.
Gzip / Brotli Compression
- Enable gzip (HTML, CSS, JS can reduce size by 70%).
- Enable Brotli (more efficient than gzip, suitable for modern browsers).
Continuous Optimization
Optimize caching strategy (adjust max-age).
Analyze CDN logs (reduce origin requests). When the CDN node does not cache the user's requested resource, it will fetch the resource from the origin server, a process known as origin request. This involves cache configuration optimization, edge computing, prefetching, origin merge, intelligent routing, etc.
Global acceleration optimization (CloudFront + Edge Location).
SLB/F5
Load Balancer (SLB stands for Server Load Balancer). F5 is a company that provides enterprise-level hardware load balancers.
SLB is generally provided by common cloud service providers, such as Alibaba Cloud SLB, AWS ELB, Tencent Cloud CLB, etc.
SLB is suitable for cloud-based microservice architectures, while F5 is suitable for private clouds and data centers.
The workflow of SLB connecting to Nginx is roughly as follows: after the user's request is received by the SLB load balancer, the SLB distributes the request to the Nginx server cluster according to the load balancing algorithm (such as round-robin, least connections, IP hash). Nginx receives the request passed by SLB and reverse proxies it to the corresponding web microservice (Spring Boot, Node.js) based on different URLs.
SLB Practical Use
- Create SLB with cloud service providers, add backend Nginx server instances, and set health checks (e.g., check Nginx port 80 to confirm if it is active, or configure health check interfaces).
- Preferably terminate HTTPS at SLB, SLB handles HTTPS (SSL), then forwards it to Nginx via HTTP (reduces Nginx load).
- E-commerce and payment systems often need to maintain user sessions. In some application scenarios, user requests need to be handled by the same backend server consistently, otherwise, it may lead to issues such as lost login status, payment anomalies, and lost shopping cart data.
SLB Solution, requires cloud load balancing (such as AWS ELB, Alibaba Cloud SLB) to support Sticky Session.
- Can be based on cookies. SLB sets a Cookie (such as AWSALB) on the first request. All subsequent requests carry this Cookie, and SLB parses it to route the request to the same backend server.
- Based on IP hash. SLB calculates a hash value based on the user's IP address and fixes requests from the same IP to the same server. Suitable for short-term session binding but not for scenarios where IP changes (such as mobile users switching networks).
Nginx Solution, can bind sessions through ip_hash or Sticky Cookie.
upstream backend {
ip_hash; # Ensure requests from the same IP are allocated to the same server
server 192.168.1.10;
server 192.168.1.11;
}
upstream backend {
server 192.168.1.10;
server 192.168.1.11;
sticky cookie srv_id expires=1h domain=.example.com path=/;
}Distributed Session, servers are multi-instance, relying solely on session binding may have issues. If the bound server goes down, the user session is lost. Use Redis to store sessions so that even if load balancing directs to different servers, sessions can be shared. Essentially, all servers can access the same session data, ensuring that even if SLB load balances to different servers, the user's shopping cart and login status are not lost.
- Nginx HA solution for high availability. Nginx itself does not have high availability features, so third-party tools are needed to achieve a high availability architecture. Mainly rely on the following technical solutions:
- Keepalived + Nginx
- LVS (Linux Virtual Server) + Keepalived + Nginx
- Cloud Nginx HA (cloud load balancing + Nginx)
Details reference
Nginx Load Balancing Configuration
If Nginx behind SLB also needs to perform secondary load balancing to backend servers, configure upstream.
# Load balance to backend application servers
upstream backend_servers {
server 192.168.2.10:8080 weight=3;
server 192.168.2.11:8080 weight=2;
server 192.168.2.12:8080 weight=1;
}
server {
listen 80;
server_name www.example.com;
location / {
proxy_pass http://backend_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}Gateway
Gateway is the entry point for service calls, responsible for routing distribution, authentication, traffic control, circuit breaking, and rate limiting.
Request Routing
- Gateway forwards client requests to the correct microservice (Server).
- Use dynamic routing to discover and call backend microservices through Nacos, reducing hardcoding.
Authentication & Authorization
- Use Spring Security + JWT to verify user identity and intercept unauthorized requests.
- Avoids the need for all microservices to repeatedly implement authentication, reducing development complexity.
Rate Limiting & Circuit Breaker
- Combine with Sentinel for traffic control and circuit breaking, preventing system overload.
- If a microservice is abnormal, the gateway can return friendly prompts or degrade processing.
Note
Sentinel
Sentinel is an open-source traffic control and circuit breaking component for distributed service architecture by Alibaba.
Request Filtering
- Can validate parameters and intercept malicious requests (such as SQL injection, XSS attacks).
- Provides black and white list mechanisms to restrict access sources.
Load Balancing
- Combine with Ribbon, the gateway can distribute requests among multiple microservice instances, improving availability.
Request Logging & Monitoring
- Record all API request logs and combine with ELK, Prometheus for monitoring and analysis.
For more details, please reference
Nacos
Nacos Naming and Configuration Service is an open-source dynamic service discovery, configuration, and management platform by Alibaba, aimed at helping developers build cloud-native applications and microservice architectures.
Service Registration and Discovery Principle
Service Registration
- Service provider registers service on startup:
When the service provider (Service Provider) starts, it sends a registration request to the Nacos Server through the Nacos client SDK.
Registration information includes service name, IP address, port number, health status, metadata, etc.
- Nacos Server stores service information:
After receiving the registration request, Nacos Server stores the service instance information in its internal registry.
The registry is a distributed data store that supports high availability and data consistency.
- Heartbeat mechanism to maintain service activity:
The service provider periodically sends heartbeat packets to the Nacos Server to indicate that it is in a healthy state.
If the Nacos Server does not receive a heartbeat packet within a certain period, it considers the service instance unavailable and removes it from the registry.
Service Discovery
- Service consumer queries service list:
The service consumer (Service Consumer) sends a service discovery request to the Nacos Server through the Nacos client SDK.
The request specifies the service name to be discovered.
- Nacos Server returns the service instance list:
Nacos Server queries the available service instance list from the registry based on the service name and returns it to the service consumer.
The returned information includes the service instance's IP address, port number, health status, etc.
- Load balancing to call services:
The service consumer selects an instance to call based on the returned service instance list and the load balancing strategy (such as round-robin, random, weight, etc.).
Dynamic Configuration Management, Service Health Check
The principle is roughly the same as above, requiring Nacos Server to play an intermediary coordination role.
Ribbon
Netflix's open-source client-side load balancer, mainly used to achieve load balancing for service calls in distributed systems. After 2018, Netflix announced that Ribbon entered maintenance mode and no longer actively develops new features.
Spring Cloud recommends using Spring Cloud LoadBalancer as a replacement for Ribbon.
Ribbon Working Principle
- Obtain service instance list:
Ribbon obtains the target service's instance list from the service registry (such as Eureka).
- Load balancing selection:
Select an instance from the instance list based on the configured load balancing strategy (such as round-robin, random, etc.).
- Initiate call:
Initiate a call to the selected service instance.
- Fault handling:
If the call fails, Ribbon retries other instances based on the configured retry mechanism.
- Health check:
Periodically check the health status of service instances and remove unhealthy instances.
Feign
Feign is the preferred RPC framework for Spring Cloud microservice architecture, used for remote calls to other microservices.
Compared to RestTemplate, it is more concise, easier to maintain, and supports Ribbon load balancing, Nacos service discovery, and Sentinel degradation.
In the diagram, multiple Server microservices communicate with each other through Feign + Ribbon for remote calls. For example:
- Gateway calls backend microservices (such as order service calling product service): Feign handles service calls, Ribbon handles load balancing.
- Internal calls between microservices (such as user service calling payment service): Feign makes the call like a local method, hiding HTTP details.
Distributed Task Scheduling Module
Distributed task scheduling is mainly used to manage and execute scheduled tasks, batch processing tasks, big data tasks, etc., ensuring tasks can be executed in parallel on multiple servers, failover, and high availability.
In monolithic applications, @Scheduled or crontab is usually used to execute scheduled tasks. However, in microservice architecture, single-machine scheduling has the following problems:
- Single point of failure (SPOF): If the task scheduling server goes down, all tasks will fail.
- Performance bottleneck: A single node's task processing capability is limited, making it difficult to support large-scale task scheduling.
- Concurrency conflicts: Multiple instances may execute the same task simultaneously, leading to data inconsistency.
- Manual scaling difficulty: Single-machine tasks cannot automatically load balance, limiting scalability.
Distributed Task Scheduling Module Solutions
- XXL-JOB: Lightweight, open-source, supports multiple languages, suitable for internet companies.
- Elastic-Job (based on Zookeeper): Suitable for big data, data synchronization, scheduled tasks.
- Spring Cloud + Quartz: Suitable for Spring Boot microservice architecture.
Core Functions of Distributed Task Scheduling
- Task Sharding (Shard): Split large tasks into multiple small tasks, processed in parallel by different machines, improving task execution efficiency.
- Task Failure Retry & Compensation: Automatically retry failed tasks or manually compensate execution.
- High Availability of Task Scheduling: Task scheduling without single point of failure, supporting master-slave switch, such as Leader election mechanism (Zookeeper). When a task fails, it automatically migrates to other nodes, ensuring tasks are executed on time.
- Dynamic Task Management: Through the web console, dynamically add, delete, modify tasks, and support online debugging.
- Task Execution Logs & Monitoring
Practical Cases
- E-commerce order timeout cancellation
Automatically cancel orders that are not paid within 30 minutes after creation.
- Regular data synchronization
Synchronize user data from MySQL to Elasticsearch every day at 1 AM for search purposes.
- Crawler tasks
Regularly crawl product information from major websites and store it in the database.
Elasticsearch
Elasticsearch (ES) is a distributed search and analysis engine mainly used for full-text search, log analysis, real-time data query, etc. Its main roles in microservice architecture include:
- Full-Text Search
- Suitable for e-commerce, content management, social platforms, etc., to achieve fast search.
- For example: Searching for products on JD.com or Taobao, users can quickly return relevant products by entering "iPhone".
- Log Analysis
- Combine with Logstash + Kibana (ELK/EFK) for monitoring logs and troubleshooting.
- For example: Collecting Nginx and microservice logs into ES for real-time query by operations personnel.
- Real-Time Data Query
- Faster than traditional database queries, suitable for large-scale data query scenarios.
- For example: Querying historical transaction records in financial systems, much faster than MySQL.
- Recommendation System & Data Analysis
- Combine with machine learning (ML) and big data (Spark, Flink) for personalized recommendations.
- For example: E-commerce recommends products based on user search history.
Elasticsearch vs Traditional Database (MySQL)
| Feature | Elasticsearch | MySQL (Relational Database) |
|---|---|---|
| Data Storage | Distributed storage, supports big data | Single or master-slave storage |
| Query Speed | Uses inverted index, fast query | SQL query, slow query |
| Full-Text Search | ✅ Powerful | ❌ Not suitable |
| Structured Query | ✅ Supports (aggregation, filtering) | ✅ Powerful |
| Real-Time | ✅ Millisecond-level query | ❌ Slower |
| Scalability | ✅ Horizontal scaling (up to PB level data) | ❌ Limited scalability |
| Transaction Support | ❌ Does not support transactions | ✅ ACID transaction support |
| Data Consistency | Eventual consistency | Strong consistency |
| Applicable Scenarios | Search, log analysis, big data query | Transactions, order management, OLTP systems |
Fast Performance
Elasticsearch query speed is usually 10 to 100 times faster than MySQL, especially in scenarios such as full-text search, big data query, and fuzzy matching. Key Reason: Elasticsearch's inverted index (Inverted Index).
In MySQL, data storage is based on B+ tree index, while in Elasticsearch, the core technology is the inverted index (Inverted Index).
Inverted Index is a data structure specifically used for full-text search, similar to the index page of a book:
- MySQL needs to scan a large amount of data during queries, especially for LIKE '%xxx%' queries, which are very inefficient.
- Elasticsearch first splits the data into tokens and then establishes an index mapping. During queries, it directly finds the relevant documents, making it extremely fast.
Others
- Elasticsearch uses a distributed architecture, where data is split into multiple shards, and multiple nodes can query in parallel, making it faster than MySQL's single-machine query.
- Elasticsearch uses file system cache and Lucene cache to store query results, making repeated queries extremely fast.
- Elasticsearch supports Trie Tree (prefix tree) and FST (finite state machine), suitable for fast keyword matching.
Amazon S3
Amazon S3 (Simple Storage Service) is an object storage service provided by AWS for storing, backing up, and distributing large-scale data.
- Supports PB-level storage, can store images, videos, audio, logs, database backups, etc.
- Object storage, different from traditional file storage and block storage.
- 99.999999999% (11 nines) data durability to prevent data loss.
- 99.99% high availability, data distributed across multiple AWS data centers (Regions).
Files are stored as "objects" rather than folder/directory structures. Each object has a unique Key (filename) for access.
In this architecture diagram, Amazon S3 is used as a distributed file storage component, mainly for storing and managing large-scale unstructured data, such as:
- Images, videos, logs, backup files, and other unstructured data.
- Static resource files (such as website images, CSS, JavaScript).
- Database backups (such as MySQL backup files).
Microservices can store metadata in Elasticsearch for indexing and fast querying, while actual files are stored in Amazon S3. Suitable for e-commerce, social platforms, document management systems.
Collaboration of S3 with MySQL and Redis
- MySQL stores structured data, not suitable for storing large files, so large files are stored in S3, and MySQL only stores the path information.
- Redis is used to cache frequently accessed file metadata, improving query efficiency.
- S3 is responsible for storing actual file data, avoiding excessive local storage on the server.
Redis
Redis (Remote Dictionary Server) is a high-performance distributed cache and NoSQL database used to store key-value data. Its main features include:
- Ultra-fast read and write (based on memory, supports over 100,000 QPS).
- Multiple data structures (String, List, Set, Hash, ZSet, Bitmap, etc.).
- Supports persistence (RDB, AOF).
- Supports distributed architecture (master-slave replication, sharding, sentinel, cluster).
In this microservice architecture diagram, Redis is mainly used for:
- Caching hot data (such as user information, product data, order status, etc.).
- Distributed session management, storing user login status to avoid session loss.
- Distributed lock (implemented based on Redis SETNX, controlling resource access in high concurrency scenarios).
- Message queue (Stream), buffering asynchronous tasks, decoupling business logic.
- Leaderboard & counter (such as PV, UV statistics, like, voting systems).
Redis Sentinel Mode
Redis Sentinel Mode is a high availability architecture used to automatically monitor Redis servers, failover, and notification. Its main functions include:
- Monitoring Redis master-slave instances (detecting if the master server is down).
- Automatic failover (if the master server goes down, automatically promote a slave server to master).
- Client notification (informing Redis clients of the new master server address).
- Coordinating multiple Redis servers in cluster mode.
Redis Sentinel Mode Working Principle
In the Redis master-slave architecture (as shown in the Redis high availability mode), Sentinel Mode ensures the high availability of Redis servers:
- Redis Master-Slave Architecture
- The master server (Master) handles read and write requests and synchronizes data to the slave servers (Slave).
- The slave servers (Slave) provide read-only access and can be used for data backup and load balancing.
- Sentinel Process
- The Sentinel process continuously monitors the status of the master Redis server (PING).
- If the master server goes down, the Sentinel promotes one of the slave servers to the new master server.
- Notifies clients of the new master server through the publish/subscribe mechanism.
Cluster Mode (Redis Cluster)
Redis Cluster is Redis's distributed architecture used to solve issues such as single-machine Redis capacity, throughput, and single point of failure. It achieves high availability and horizontal scaling through data sharding and decentralized design.
Core Features of Redis Cluster
- Data Sharding
- Uses a hash slot partitioning mechanism to distribute data across different Redis nodes.
- Each Redis node is responsible for a portion of the 16384 hash slots, balancing data storage and avoiding overloading a single node.
- Decentralized Architecture
- No single point of failure, all nodes store cluster information, and it does not rely on a central scheduling node (unlike Sentinel, which relies on Sentinel).
- Any node can accept client requests and forward them to the correct node.
High Availability (Failover Mechanism)
- Each master node has slave nodes, and when the master node goes down, the cluster automatically elects a new master node.
Horizontal Scaling
- Can dynamically add/remove nodes, suitable for large-scale storage needs (such as PB-level data).
- Clients can access new nodes through hash slot reallocation without manually modifying the code.
Multi-Master Architecture
- Supports multi-master (Master-Master), dispersing read and write pressure and improving performance.
Redis Cluster vs. Traditional Redis Comparison
| Comparison Item | Redis Single Machine | Redis Sentinel | Redis Cluster |
|---|---|---|---|
| Architecture | Single node | Master-Slave | Multi-Master |
| Scalability | Cannot scale | Read scaling | Horizontal scaling |
| High Availability | No, single point of failure | Master-Slave switch | Master-Slave switch |
| Data Sharding | Not supported | Not supported | Supported |
| Throughput | Limited by single machine | Limited by master node | High throughput |
| Master-Slave Switch | Not supported | Automatic switch | Automatic switch |
| Data Consistency | High (single machine) | High (replication consistency) | Eventual consistency |
| Operational Complexity | Simple | Moderate | Complex |
| Usage Scenarios | Small projects, low concurrency | High availability but low traffic | High concurrency, large-scale storage, high availability scenarios |